| Teil 16 : Sortieralgorithmen |
Wir befassen uns in diesem Kapitel um einige grundlegende Sortierverfahren
und ihrer Effizienz. Um zu beurteilen, wie schnell Algorithmen arbeiten,
befassen wir uns erstmal, welche Beurteilungskriterien es für Algorithmen
gibt. Allgemein gibt es zwei Arten von Sortierfunktionen: interne und externe.
Internes Sortieren ist das Sortieren komplett im Speicher des Rechners.
Als externes Sortieren bezeichnet man Sortierverfahren, wo die Daten auf
externen Speichermedien (z.B. festplatten) liegen und die Daten nicht komplett
in den Speicher gelesen werden können. Bei den folgenden Beispielprogrammen
wird auf die Dateien struktur.h , struktur.c , sortier.h
und sortier.c zurückgegriffen. In sortier.h sind alle
Prototypen der hier vorgestellten Sortieralgorithmen und in sortier.c
die entsprechenden Module.
| Grundlagen zur Algorithmenbeurteilung |
Ein wichtiger Betrachtungspunkt bei Algorithmen ist die Zeitkomplexität.die
eine allgemeine Größenordnung des Ablaufs des betreffenden Algorithmus
darstellt. Sie ist unabhängig von der Programmiersprache und ist eine
Eigenheit des verwendeten Algorithmus. Zeitkomplexitäten werden in
der Form O( ZK ) dargestellt, wobei ZK der Zeitkomplexität
der zum Ablauf benötigten Schritte bei n Elementen entspricht.
Sie gibt jeweils die höchste Potenz von n an, ohne Faktoren.Z.B.
O(
n2 ) wenn bei n Elementen 3n2+n
Schritte für den Algorithmus benötigt werden. Eine weitere Betrachtungen
könnte analog dazu die Speicherkomplexität sein.
| Insertion Sort |
Ein einfaches Sortierverfahren besteht daraus alle neuen Elemente wie
beim Einreihen von Spielkarten auf der Hand nach und nach einzureihen.
Das kann man leicht mit unseren bereits bekannten Listen realisieren. Wir
erstellen eine Liste und Reihen neue Elemente nach und nach ein.
| EVL *InsertionSort ( EVL *Liste, double Wert )
{ EVL *temp = Liste;} |
Bei jedem Aufruf werden die neuen Elemente eingereiht. Bei einer leeren
Liste, wird das neue Element der Listeninhalt. Ansonsten wird die Liste
mit der Hilfsvariablen temp entlanggegangen und eingereiht, wenn
Wert
größer als der aktuelle Listenwert ist. Dadurch erzeugt man
eine aufsteigende Sortierung. Wenn das Listenende erreicht ist, wird das
neue Element hinten angehängt und gegebenenfalls werden die letzten
beiden Elemente vertauscht. Das können wir durch ein testprogramm
schreiben, indem mehrere Werte in die Liste eingefügt werden. Anschließend
wird die Liste angezeigt.
| #include <stdio.h>
#include "struktur.h" #include "sortier.h" void main (void)
/* neue Liste */} |
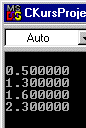
Wie man sehen kann, werden alle neuen Werte richtig eingereiht. Zur
Übung könnten sie das Modul so umschreiben, das es abwärts
sortiert, also vom höchsten zum niedrigsten Wert.
| Bubble Sort |
Ein weiteres einfaches Sortierverfahren ist Bubbelsort. Es wird das
erste Element mit allen weiteren verglichen. Wenn ein Element gefunden
wurde das kleiner ist, so werden beide vertauscht. Dann vergleicht man
das zweite mit allen folgenden Felder und vergleicht es wieder mit dem
Rest, und so weiter. Wenn man dies mit allen gemacht hat, so ist am Ende
das Feld sortiert. Den Namen hat BubbleSort dadurch, das auch diese Weise
nach und nach alle kleinsten Elemente wie Luftblasen (engl. bubbles) nach
oben steigen, also an den Anfang der Liste. Ein Modul, was auf unseren
Listen basiert, sieht wie folgt aus.
| EVL *BubbleSort ( EVL *Liste )
{ EVL *Rest, *Akt = Liste;} |
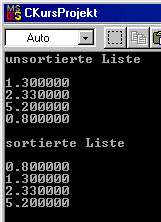
Testen wir den Algorithmus, in dem wir Werte nach belieben in eine Liste
setzen und diese dann sortieren lassen. Wie wir sehen sortiert dieser Algorithmus
das Feld aufsteigend. Zur Übung könnte er in einen Sortieralgorithmus
geändert werden, der absteigend sortiert.
| #include <stdio.h>
#include "struktur.h" #include "sortier.h" void main (void)
EVL *Liste = NULL;} |
| Quick Sort |
Dieser Sortieralgorithmus basiert auf dem Prinzip "Teile und Herrsche",
welches beim sortieren besagt, das die Reihe geteilt wird und jedes dieser
Einzelelemente sortiert werden. Jedes dieser Einzelteile wird wiederum
geteilt, und so weiter. Dabei wird jedes rechte Element als zerlegendes
Element benützt, d.h. es ist das Element, was an die richtige Position
in der Reihung gebracht werden soll. Dabei wird das linke Teilelement geprüft,
ob es größer als das rechte Element ist. Wenn ja, so werden
beide miteinander vertauscht. Dies wird solange gemacht, bis sich die beiden,
der linke und rechte "Teiler" kreuzen. Im folgenden wird der Algorithmus
mit Ganzzahlen (int) realisiert.
| void quicksort (int *sort, int l, int r)
{ int i, j, Temp;} |
Wir arbeiten hier mit ganz einfachen int-Feldern. Mit einem Beispielprogramm
testen wir, ob das Sortierverfahren auch funktioniert.
| #include <stdio.h>
#include <stdlib.h> #include "struktur.h" #include "sortier.h" #define groesse 10 /* Feldgroesse */ void main (void)
int *feld = malloc (groesse * sizeof(int) );} |
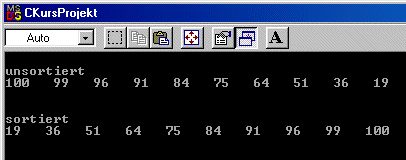
Ok, wie man sieht ist das Eingangsfeld nicht ganz unsortiert, aber da
wir eine Aufwärtssortierung vornehmen ist es in unserem Sinne nicht
in der entsprechenden Folge. Wer möchte kann gerne ein Programm erstellen,
welches eine beliebige Ziffernfolge einliest und sortiert.
| sortieren mit Bäumen |
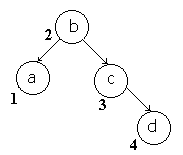
Kommen wir nun zu einem der Vorteile, die einem ein binärer Baum bietet. Es ist unheimlich leicht, wenn man von Anfang an bestimmte Einsetzmodalitäten beachtet eine sortierte Liste mit Hilfe eines Baumes zu programmieren. Dazu gehen wir davon aus, das wir Anfangs einen leeren Baum haben. In dem Fall ist natürlich das neu eingefügte Element, der Wurzelknoten. Fügen wir nun weitere Elemente hinzu so sortieren wir ihn nicht in dem Sinn, das Elemente vertauscht werden, sondern hängen das neue Element wie folgt ein. Elemente die kleiner oder gleich dem momentanen Element sind, werden linksseitig weitergereicht, bis sie einen freien Platz finden, ansonsten rechtsseitig weitergereicht. Ist ein Element NULL , so hat das neu eingefügte Element seinen Platz gefunden und wird dort angehängt. Hört sich verworren an, ist aber recht einfach, wie man am folgenden Schema sehen kann, wenn wir die Buchstaben b , c , d und a in einen Baum einfügen..
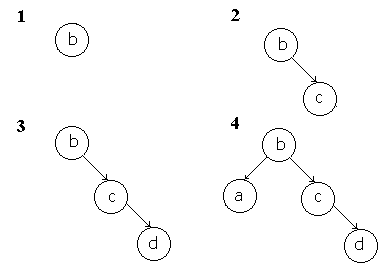
Sieht noch nicht sonderlich sortiert aus, oder etwa doch ? Mit der Einreihungsvorschrift
können wir schon sagen, wo ein kleineres Element als das Augenblickliche
sich befinden müßte. Wenn wir das sooft tun, bis wir kein neues
Element vorfinden, sondern ein NULL, so wissen wir, das dies das
Kleinste sein muß. Wenn wir uns so durch den Baum hangeln bekommen
wir ganz elegant eine Sortierung vom Kleinsten zum Größten.
Ein solches Modul sieht wie folgt aus.
| Knoten *SortBaumEinf (Knoten *Baum, char Wert)
{ /* neues Knotenelement */} |
Der Name soll an das Einfügen in sortierte Bäume erinnern.
Durch dieses Vorgehen erhalten wir wie gesagt einen vorsortierten Baum,
der seine Sortiertheit aber nur durch unsere Spezielle Ausgabeweise bekommt,
er funktioniert also nur im Zusammenhang mit dem Ausgabemodul als sortierter
Baum. Genug von der Ausgabe geredet, schauen wir sie uns einmal an.
| void SortBaumAusgeben (Knoten *Baum)
{ if (Baum != NULL)} |
Wenn wir uns die Knoten anschauen, in welcher Reihenfolge sie ausgegeben werden, dann sehen wir, das hier zuerst vom Kleinsten zum Größten hin sortiert ausgegeben wird.
Probieren wir wie gewohnt unsere Theorie in der Praxis mit einem Beispielprogramm
aus. Dazu fügen wir, wie im Beispiel, nacheinander die Buchstaben
b
, c , d und a in den Baum ein und führen
unser Ausgabemodul aus.
| #include <stdio.h>
#include "struktur.h" #include "sortier.h" void main (void)
Knoten *Baum = NULL;} |
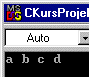
Und wie erwartet wird eine sortierte Buchstabenliste ausgegeben. Diese
Module kann man natürlich nun leicht umändern, damit sie mit
Zahlenwerten funktionieren. Wer es ganz elegant lösen will, kann aus
die Ausgaben auf einen Stack
packen oder in eine Liste des
Typs EVL einsetzen. Eine weitere angenehme Eigenschaft
ist, das man schnell Zugriff auf das Kleinste und Größte Element
hat. Da wir wissen, das alle linksseitig eingeordneten Elemente kleiner
als die Vorgängerknoten sind, brauchen wir also nur noch solange linksseitig
herunter zu wandern, bis das letzte Element erreicht ist. Als Rückgabewert
erhalten wir somit das kleinste Element im Baum.
| Knoten *MinElement(Knoten *Baum)
{ if (Baum == NULL) return Baum;} |
Analog können wir das mit dem größten Element machen,
nur das wir rechtsseitig suchen.
| Knoten *MaxElement(Knoten *Baum)
{ if (Baum == NULL) return Baum;} |
Wenden wir uns noch einmal unserem Beispielprogramm zu und erweitern
wir es, damit auch das kleinste und größte Element mit ausgegeben
wird. Wie man sieht muß abgefangen werden, ob der Baum NULL
ist, da sonst natürlich nicht auf ein Element key zugegriffen
werden kann.
| #include <stdio.h>
#include "struktur.h" #include "sortier.h" void main (void)
Knoten *Baum = NULL;} |
| Heap Sort |
Für das Heapsortverfahren benutzen wir Heaps, also sortierte komplette Bäume im Sinne der Heapbedingung. Für unsere Routine werden wir unsere beliebten int-Felder benutzen.
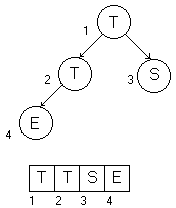
Der Ausgangspunkt bei Heapsort ist eine Liste. Diese wird in einen Heap umgewandelt. Wie man sich denken kann wird die Heapbedingung bei einer solchen Umwandlung schnell verletzt. Wir müssen demzufolge den noch fehlerhaften Heap umwandeln in einen Heap. Das Besondere ist diesmal, das die Heapbedingung so aussieht, das die Werte der Töchterknoten größer sind. Das Schema zeigt, wie Bei Schritt 1 der größte Wert an der letzten Stelle des dem Heap entsprechenden Feldes gesetzt wird (rot markiert). Bei Schritt 2 wird die zweitgrößte Zahl an dir vorletzte Stelle des Feldes gerückt, u.s.w. Weiterhin sind die einmal nach unten gewanderten Elemente nicht mehr in der Betrachtung des Feldes relevant. Daher wird das Feld ständig verkleinert und die momentan betrachtete Feldlänge schrumpft jedesmal ( --N ). Man fragt sich natürlich, wieso nicht mit altbekannten Sortierverfahren für Felder (wie zuvor beschrieben) gearbeitet wird. Durch die Heapstruktur geht das erstellen der Liste relativ schnell vonstatten und man muß weniger Quervergleiche anstellen.

Das Umwandeln in einen Heap bewirkt folgendes Modul, das den Inhalt
des Elements am Index k den Heap "herunterbewegt". Bei dem Beispielfeld
handelt es sich um ein Feld des Typs int mit N Feldelementen
des Feldes feld.
| void downheap (int *feld, int N, int k)
{ int j,v;} |
Das oben vorgestellte Modul downheap wird nun benötigt um
Stück für Stück den Heap in der Weise zu sortieren, das
an den Blättern mit dem höchsten Index k im Feld
nach und nach die größten Werte mit downheap dorthin
bewegt werden. Aufgerufen wird Heapsort mit dem zu sortierenden Feld und
der Anzahl der Feldelemente N.
| void heapsort (int *feld, int N)
{ int k, t;} |
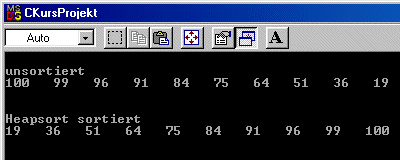
Als Demonstrationsprogramm benutzen wir das aus dem vorigen Sortierverfahren.
Natürlich mit dem Unterschied, das wir hier das Modul heapsort
benutzen.Aufgerufen wird es mit dem zu sortierenden Feld und der höchstwertigsten
Index, also bei 10 Elementen ist der höchste Index 9 ( Feld[0]
- Feld[9] ).
| #include <stdio.h>
#include <stdlib.h> #include "struktur.h" #include "sortier.h" #define groesse 10 /* Feldgroesse */ void main (void)
int *feld = malloc (groesse * sizeof(int) );} |
| die Datei sortier.h und sortier.c |
In den Beispielprogrammen wurde eine Headerdatei sortier.h
eingebunden,
die alle besprochenen Beispielalgorithmen enthält. Wie das einbinden
erfolgt, kann man im Kapitel
über den Precompiler nochmals nachlesen.In der Datei sortier.c
enthält
die Module zu den entsprechenden Datentypen.

sortier.h & sortier.c
| ...das Obligatorische |
Autor: Sebastian Cyris PCDBascht@aol.com
Dieser C-Kurs dient nur zu Lehrzwecken! Eine Vervielfältigung ist ohne vorherige Absprache mit dem Autor verboten! Die verwendete Software unterliegt der GPL und unterliegt der Software beiliegenden Bestimmungen zu deren Nutzung! Jede weitere Lizenzbestimmung die der benutzten Software beiliegt, ist zu beachten!